Ideogram 4.0
Первая open-weight модель от Ideogram, их линейка давно лидирует в рендеринге текста на изображениях и 4.0 поднимает планку ещё выше Не дообучение существующей модели, а полностью новая foundation-модель, обученная с нуля на 9.3 миллиарда параметров Впервые на моей памяти можно у
5 мин 1 0 0
Источник: t.me

В материале0 комментариев
Источник: Telegram-канал Neurogen, публикация от 2026-06-03T20:13:12+00:00. Материал расширен в формат лонгрида: добавлен контекст, источники и практические выводы.
Что произошло
Первая open-weight модель от Ideogram, их линейка давно лидирует в рендеринге текста на изображениях и 4.0 поднимает планку ещё выше
Не дообучение существующей модели, а полностью новая foundation-модель, обученная с нуля на 9.3 миллиарда параметров
Впервые на моей памяти можно указывать через json где должен находится каждый объект и текст бокс
Мультиязычный рендеринг текста, вроде sota
Нативное разрешение 2К и соотношения сторон до 6:1
Управление цветами через hex коды в промпте
Ну и наконец, структурированные json-промпты, если это вам ничего не говорит, то объясню вкратце, когда мы описываем напрямую модели текстом наш промпт, так или иначе это будет просто шквал букв которые образуют какой то текст и распознавать их модель будет соотвественно также
Но когда мы даем модели промпт с помощью json, то мы уже направляем модели определенный набор данных и воспринимает ии их как конкретные данные структурированные, надеюсь понятно объяснил
Ideogram-4-fp8 — работает на любом пк
Пойдет на минимальных 12 ГБ (RTX 3060 12GB, RTX 4070), но лучше всего от 24 ГБ (RTX 3090, RTX 4090, RX 7900 XTX)
Ideogram-4-nf4 — только CUDA
Минимально 8 ГБ, но лучше всего 12-16 для идеальной работы
Ideogram-4-INT8-ConvRot — для систем по старее
Те же 12 ГБ (минимум) с оффлоадингом и 24 ГБ (рекомендуемо) для полной загрузки
Также нам предлагают API (цены за картинку)
Turbo | $0.03
Default | $0.06
Quality | $0.10
Дополнительно доступны Background Remover, Character Consistency, Styles, Print on Demand, MCP-интеграция и редактируемые текстовые слои
Попробовать
Блогпост
HuggingFace
Github
Накидываем примеры в комменты
Почему это важно
Эта новость отражает общий сдвиг рынка ИИ: модели и инструменты становятся более специализированными, быстрее переходят из лабораторных анонсов в API и локальные сборки, а конкуренция всё чаще идёт не только по бенчмаркам, но и по реальным сценариям: кодинг, мультимодальность, генерация медиа, голос, агенты и стоимость инференса.
Для пользователей Neurogen это важно в прикладном смысле: такие релизы влияют на выбор моделей для разработки, контента, автоматизации, локального запуска и коммерческих продуктов. Поэтому ключевой вопрос не только в том, кто показал лучший score, а в том, где инструмент уже можно проверить, сколько он стоит, какие ограничения есть и насколько он устойчив в длинных задачах.
Что известно из источников
- ideogram-ai/ideogram-4-fp8 · Hugging Face — We’re on a journey to advance and democratize artificial intelligence through open source and open science.
- ideogram-ai/ideogram-4-nf4 · Hugging Face — We’re on a journey to advance and democratize artificial intelligence through open source and open science.
- bertbobson/Ideogram-4-INT8-ConvRot · Hugging Face — We’re on a journey to advance and democratize artificial intelligence through open source and open science.
- Just a moment...
- Ideogram 4.0 | Ideogram — Ideogram 4.0 is an open weight image model: dense text rendering across languages, object and text placement through bounding box control, and 2K output that doesn't look AI generated.
- GitHub - ideogram-oss/ideogram4: Ideogram 4: Open image model at the forefront of design · GitHub — Ideogram 4: Open image model at the forefront of design - ideogram-oss/ideogram4
Практический вывод
Если речь идёт о модели или API, её стоит оценивать по трём параметрам: качество на ваших задачах, стабильность в длинной сессии и итоговая цена одной полезной операции. Если речь о генерации медиа или голосе, дополнительно важны права использования, скорость, локальный запуск, качество русского языка и повторяемость результата.
Медиа из Telegram







Дальше по теме
Еще несколько материалов из этого раздела.
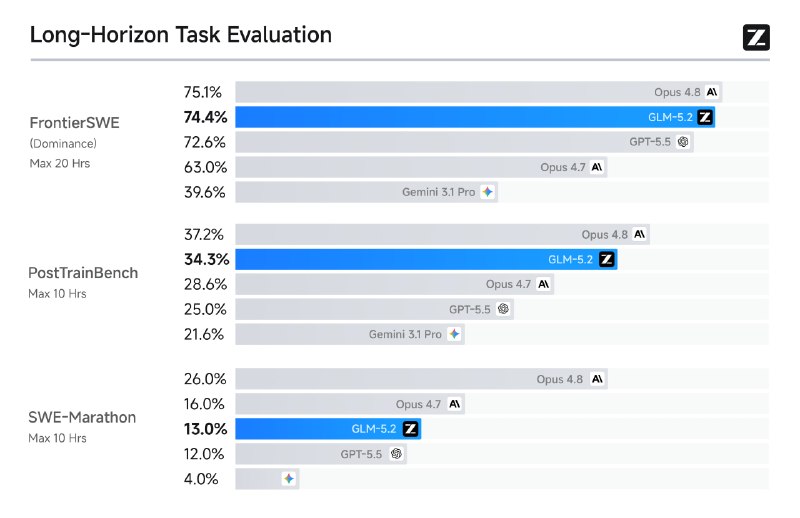 GLM-5.2Обновка подъехала, китайский опенсорс кодер, долгие сессии кодинга, авто ресерч и тд. подобрался к Claude Opus 4.8 в плотную Контекст 1М токенов, тренировали модель специально под длинноконтекстные кодинг сценарии Появились уровни thinking effort (включая Max) можно балансировать
GLM-5.2Обновка подъехала, китайский опенсорс кодер, долгие сессии кодинга, авто ресерч и тд. подобрался к Claude Opus 4.8 в плотную Контекст 1М токенов, тренировали модель специально под длинноконтекстные кодинг сценарии Появились уровни thinking effort (включая Max) можно балансировать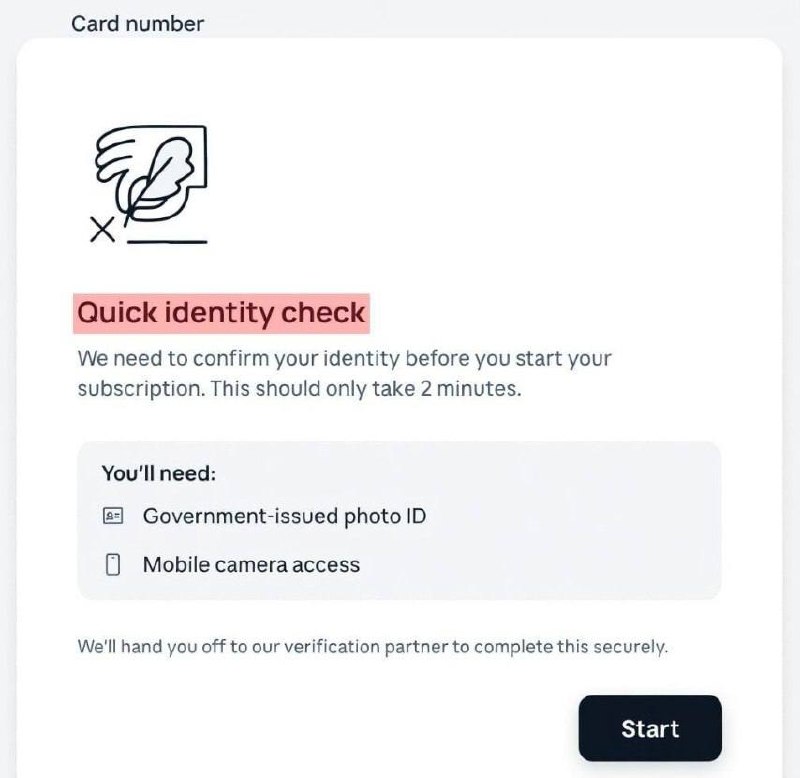 Как вам новость, что Антропики в июле введут подтверждение личности по паспорту и селфи?С 8 июля компания может потребовать подтверждения возраста или личности пользователя под предлогом повышения уровня безопасности Если не подтвердил личность, обрубают доступ к моделямGLM-5.2Обновился китайский флагман для кодинга, пока только анонс, сам релиз на следующей неделе, сейчас в coding plan доступно Модель будет доступна всем тарифам, контекстное окно 1млн токенов, максимальный вывод 131 072 токенов, high и max рассуждения, ну и улучшенный кодинг агентскиеДоступ к Fable 5 закрыт не американцамMythos 5 и Fable 5 экстренно отключены по требованию правительства США для всех не граждан Америки Официальной версии нет, но все, включая антропиков говорят о джайлбрейке благодаря которому модели ищут уязвимости в любых базах Антропики с этим решением не согласны и обещают как
Как вам новость, что Антропики в июле введут подтверждение личности по паспорту и селфи?С 8 июля компания может потребовать подтверждения возраста или личности пользователя под предлогом повышения уровня безопасности Если не подтвердил личность, обрубают доступ к моделямGLM-5.2Обновился китайский флагман для кодинга, пока только анонс, сам релиз на следующей неделе, сейчас в coding plan доступно Модель будет доступна всем тарифам, контекстное окно 1млн токенов, максимальный вывод 131 072 токенов, high и max рассуждения, ну и улучшенный кодинг агентскиеДоступ к Fable 5 закрыт не американцамMythos 5 и Fable 5 экстренно отключены по требованию правительства США для всех не граждан Америки Официальной версии нет, но все, включая антропиков говорят о джайлбрейке благодаря которому модели ищут уязвимости в любых базах Антропики с этим решением не согласны и обещают как
Обсуждение
Обсуждение начнется с первого вопроса или полезного дополнения.
Обсуждение еще не началось
После входа можно будет задать вопрос автору или ответить другим читателям.