Kimi-K2.7-Code
Moonshot обновили свой опенсорс флагман для кодинга, за коротко время уже второй раз крупно апгрейдятся Параметров у нее 1Т, активных 32В, контекст дефолтный 256К Резкий скачок в производительности на ключевых бенчмарках, ориентированных именно на программирование и агентные сцен
4 мин 1 0 0
Источник: t.me

В материале0 комментариев
Источник: Telegram-канал Neurogen, публикация от 2026-06-12T18:00:43+00:00. Материал расширен в формат лонгрида: добавлен контекст, источники и практические выводы.
Что произошло
Moonshot обновили свой опенсорс флагман для кодинга, за коротко время уже второй раз крупно апгрейдятся
Параметров у нее 1Т, активных 32В, контекст дефолтный 256К
Резкий скачок в производительности на ключевых бенчмарках, ориентированных именно на программирование и агентные сценарии
- +21,8% на Kimi Code Bench v2
- +11,0% на Program Bench
- +31,5% на MLS Bench Lite
Код стал выглядеть эстетичнее и лучше решает комплексные ml-инженерные задачи, где раньше у опенсорсов был большой пробел
Рассуждение стало эффективнее, команда заявляет о снижении overthinking примерно на 30% относительно K2.6. На практике это значит, что модель меньше жуёт одну и ту же мысль в цепочке reasoning, быстрее приходит к ответу и тратит меньше токенов а значит, и денег пользователя на одну и ту же задачу
Сделали заметно сильнее в длинных кодинг-сессиях, лучше следует промптам и доводит сквозные задачи до конца с более высокой success rate
Это критически важно именно для агентных workflow, где модель должна самостоятельно планировать, писать, запускать и чинить код в несколько итераций
Также анонсировал скорый запуск 6x High-Speed Mode - режима с шестикратным ускорением инференса
Kimi Code
API
Hugging Face
Почему это важно
Эта новость отражает общий сдвиг рынка ИИ: модели и инструменты становятся более специализированными, быстрее переходят из лабораторных анонсов в API и локальные сборки, а конкуренция всё чаще идёт не только по бенчмаркам, но и по реальным сценариям: кодинг, мультимодальность, генерация медиа, голос, агенты и стоимость инференса.
Для пользователей Neurogen это важно в прикладном смысле: такие релизы влияют на выбор моделей для разработки, контента, автоматизации, локального запуска и коммерческих продуктов. Поэтому ключевой вопрос не только в том, кто показал лучший score, а в том, где инструмент уже можно проверить, сколько он стоит, какие ограничения есть и насколько он устойчив в длинных задачах.
Что известно из источников
- Kimi Code with K2.7 Code: Next-Gen AI Code Agent & CLI — Try Kimi K2.7 Code in Kimi Code (KFC), the ultimate AI toolkit for developers. Featuring high-performance CLI tools and Turbo-speed models to automate code generation and boost development efficiency. Experience faster, more reliable AI-powered coding today
- Kimi API Platform — Kimi K2.7 Code Open Platform, providing trillion-parameter K2.7 Code large language model API, supporting 256K long context and Tool Calling. Professional code generation, intelligent dialogue, visual reasoning, helping developers build AI applications.
- moonshotai/Kimi-K2.7-Code · Hugging Face — We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Практический вывод
Если речь идёт о модели или API, её стоит оценивать по трём параметрам: качество на ваших задачах, стабильность в длинной сессии и итоговая цена одной полезной операции. Если речь о генерации медиа или голосе, дополнительно важны права использования, скорость, локальный запуск, качество русского языка и повторяемость результата.
Медиа из Telegram

Дальше по теме
Еще несколько материалов из этого раздела.
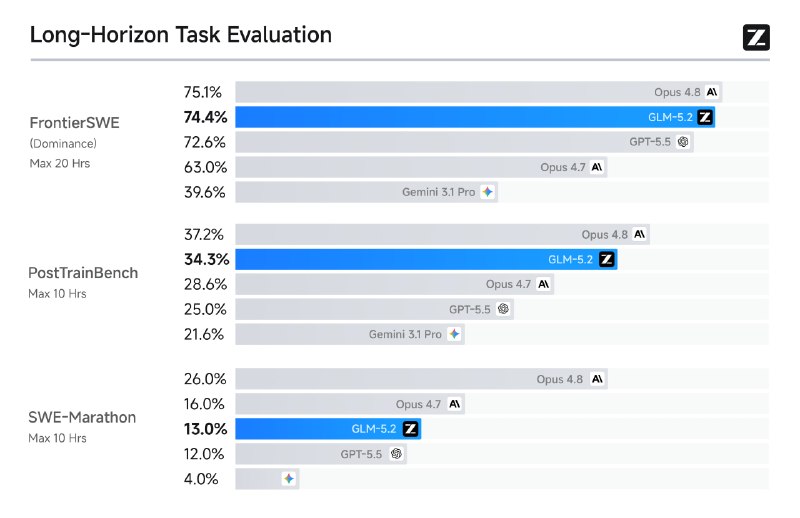 GLM-5.2Обновка подъехала, китайский опенсорс кодер, долгие сессии кодинга, авто ресерч и тд. подобрался к Claude Opus 4.8 в плотную Контекст 1М токенов, тренировали модель специально под длинноконтекстные кодинг сценарии Появились уровни thinking effort (включая Max) можно балансировать
GLM-5.2Обновка подъехала, китайский опенсорс кодер, долгие сессии кодинга, авто ресерч и тд. подобрался к Claude Opus 4.8 в плотную Контекст 1М токенов, тренировали модель специально под длинноконтекстные кодинг сценарии Появились уровни thinking effort (включая Max) можно балансировать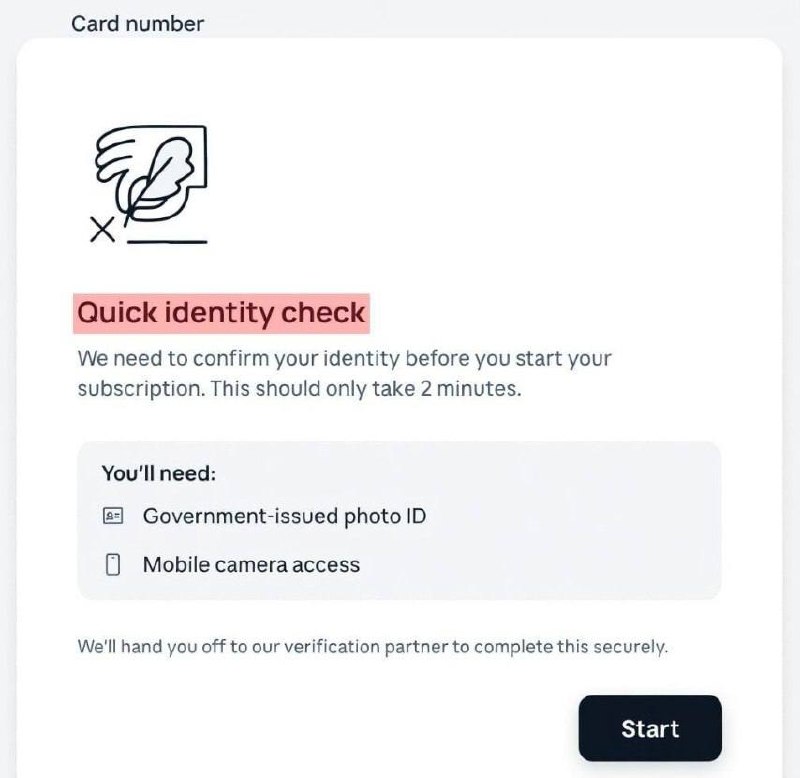 Как вам новость, что Антропики в июле введут подтверждение личности по паспорту и селфи?С 8 июля компания может потребовать подтверждения возраста или личности пользователя под предлогом повышения уровня безопасности Если не подтвердил личность, обрубают доступ к моделямGLM-5.2Обновился китайский флагман для кодинга, пока только анонс, сам релиз на следующей неделе, сейчас в coding plan доступно Модель будет доступна всем тарифам, контекстное окно 1млн токенов, максимальный вывод 131 072 токенов, high и max рассуждения, ну и улучшенный кодинг агентскиеДоступ к Fable 5 закрыт не американцамMythos 5 и Fable 5 экстренно отключены по требованию правительства США для всех не граждан Америки Официальной версии нет, но все, включая антропиков говорят о джайлбрейке благодаря которому модели ищут уязвимости в любых базах Антропики с этим решением не согласны и обещают как
Как вам новость, что Антропики в июле введут подтверждение личности по паспорту и селфи?С 8 июля компания может потребовать подтверждения возраста или личности пользователя под предлогом повышения уровня безопасности Если не подтвердил личность, обрубают доступ к моделямGLM-5.2Обновился китайский флагман для кодинга, пока только анонс, сам релиз на следующей неделе, сейчас в coding plan доступно Модель будет доступна всем тарифам, контекстное окно 1млн токенов, максимальный вывод 131 072 токенов, high и max рассуждения, ну и улучшенный кодинг агентскиеДоступ к Fable 5 закрыт не американцамMythos 5 и Fable 5 экстренно отключены по требованию правительства США для всех не граждан Америки Официальной версии нет, но все, включая антропиков говорят о джайлбрейке благодаря которому модели ищут уязвимости в любых базах Антропики с этим решением не согласны и обещают как
Обсуждение
Обсуждение начнется с первого вопроса или полезного дополнения.
Обсуждение еще не началось
После входа можно будет задать вопрос автору или ответить другим читателям.