WhisperX Portable by Neurogen
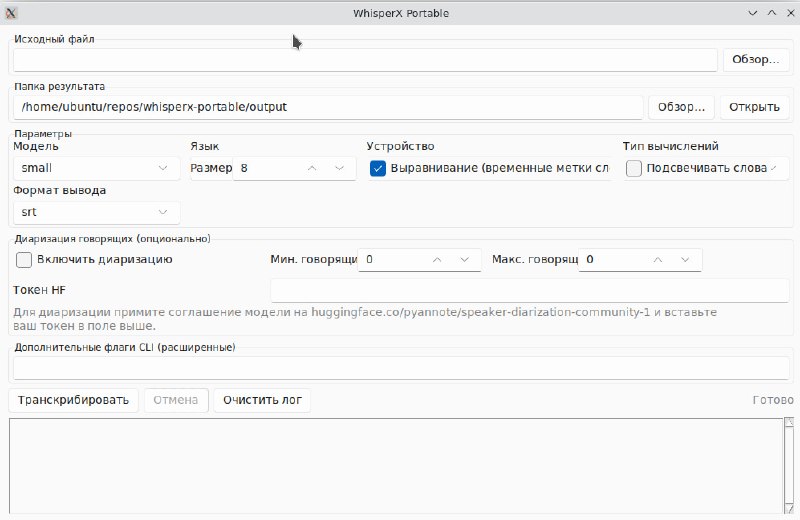
Транскрипция и диаризация Собрал портативную Windows-сборку WhisperX — это быстрое распознавание речи на базе Whisper с пословной разметкой времени и разделением говорящих. Установка одной кнопкой, без admin-прав, без CUDA Toolkit, без Anaconda. После установки папку можно скопир
6 мин 1 0 0
Источник: t.me
В материале0 комментариев
Источник: Telegram-канал Neurogen, публикация от 2026-05-14T06:28:50+00:00. Материал расширен в формат лонгрида: добавлен контекст, источники и практические выводы.
Что произошло
Транскрипция и диаризация
Собрал портативную Windows-сборку WhisperX — это быстрое распознавание речи на базе Whisper с пословной разметкой времени и разделением говорящих.
Установка одной кнопкой, без admin-прав, без CUDA Toolkit, без Anaconda. После установки папку можно скопировать на любой Windows-комп с NVIDIA-картой и просто запустить.
🔘Функционал
- расшифровка интервью, лекций, подкастов
- субтитры (SRT / VTT) к видео и стримам
- разделение по говорящим в записях встреч и созвонов
- всё локально, ничего не уходит в облако
В отличие от веб-сервисов бесплатно, неограниченно по длине, и приватно
🔘Что нужно
- Windows 10 / 11, 64-бит
- NVIDIA с драйвером R555+ (RTX или GTX 10+ серии) — будет в десятки раз быстрее
- Либо просто CPU — медленнее, но работает без видеокарты
- 8 ГБ ОЗУ минимум, 16+ ГБ для крупных моделей
- ~6 ГБ места на диске после установки + место под модели
🔘 Как поставить
1. Скачайте репозиторий ZIP-ом или git clone https://github.com/rzaev77/whisperx-portable.git
2. Распакуйте куда угодно — главное, чтобы в пути не было кириллицы (Python embeddable этого не любит)
3. Дважды кликните setup.bat. Первый раз качается ~3–5 ГБ, занимает 10–30 минут
4. После завершения — WhisperX.bat запускает GUI
Если у вас нет NVIDIA-карты, перед setup.bat запустите:
powershell -ExecutionPolicy Bypass -File tools\setup.ps1 -Backend cpu
🔘Как пользоваться
Через GUI: выбираете аудио/видео, ставите модель (large-v3 для качества, medium для скорости), язык (например ru), нажимаете «Транскрибировать». Результаты — в папке output/.
Через drag-and-drop: бросаете файл на WhisperX-CLI.bat — он сам прогонит транскрипцию с настройками по умолчанию.
Из консоли:
WhisperX-CLI.bat input.mp3 --model large-v3 --language ru --output_format srt
🔘Полезные советы
Модели: tiny → base → small → medium → large-v3. Чем больше, тем точнее и медленнее. Для русского large-v3 — оптимум.
Если не хватает VRAM (ошибка CUDA out of memory): поставьте compute_type=int8 и batch_size=4 в GUI. Так влезает даже на 6 ГБ.
Скорость: на RTX 3060 час аудио → ~3-5 минут на large-v3 с compute_type=float16. На CPU тот же час — до 30-60 минут.
Качество выше: оставьте «Выравнивание (временные метки слов)» включённым — получите точные тайминги по словам, удобно для субтитров.
Форматы: srt для субтитров, txt для чистого текста, json если нужна машинная обработка с таймкодами и говорящими.
Папка переносится: после setup.bat можно скопировать всю папку на флешку и запускать на другом компе с NVIDIA-картой. Без переустановки.
🗣 Диаризация (разделение говорящих)
Чтобы получить «Спикер 1: …», «Спикер 2: …»:
1. Регистрируетесь на huggingface.co
2. Принимаете соглашение на странице модели pyannote
3. Создаёте токен с правом чтения: https://huggingface.co/settings/tokens
4. Вставляете токен в поле «Токен HF» в GUI, ставите галку «Включить диаризацию»
Токен сохранится в config.json рядом — больше вводить не придётся.
🔘Если что-то сломалось
`Could not load library cudnn_*.dll` → драйвер NVIDIA старее R555. Обновите с [nvidia.com](https://www.nvidia.com/Download/index.aspx) или переустановите с -Backend cpu.
CUDA out of memory → меньше модель, compute_type=int8, batch_size=4.
Кириллица в консоли как ??? → у вас старая версия Windows без поддержки UTF-8 в консоли. Сама работа не пострадает, только сообщения.
Полный сброс: powershell -ExecutionPolicy Bypass -File tools\setup.ps1 -Force — стирает runtime/ и переустанавливает.
Подробности — в docs/TROUBLESHOOTING.md.
GITHUB
Почему это важно
Эта новость отражает общий сдвиг рынка ИИ: модели и инструменты становятся более специализированными, быстрее переходят из лабораторных анонсов в API и локальные сборки, а конкуренция всё чаще идёт не только по бенчмаркам, но и по реальным сценариям: кодинг, мультимодальность, генерация медиа, голос, агенты и стоимость инференса.
Для пользователей Neurogen это важно в прикладном смысле: такие релизы влияют на выбор моделей для разработки, контента, автоматизации, локального запуска и коммерческих продуктов. Поэтому ключевой вопрос не только в том, кто показал лучший score, а в том, где инструмент уже можно проверить, сколько он стоит, какие ограничения есть и насколько он устойчив в длинных задачах.
Что известно из источников
- GitHub - rzaev77/whisperx-portable · GitHub — Contribute to rzaev77/whisperx-portable development by creating an account on GitHub.
- huggingface.co
- pyannote/speaker-diarization-community-1 · Hugging Face — We’re on a journey to advance and democratize artificial intelligence through open source and open science.
- Hugging Face – The AI community building the future. — We’re on a journey to advance and democratize artificial intelligence through open source and open science.
- Wereldleider in AI-computing — NVIDIA vindt de GPU uit en stimuleert de vooruitgang in AI, HPC, gaming, creatief ontwerp, autonome voertuigen en robotica.
- Download The Latest Official NVIDIA Drivers — Download the latest official NVIDIA drivers to enhance your PC gaming experience and run apps faster.
Практический вывод
Если речь идёт о модели или API, её стоит оценивать по трём параметрам: качество на ваших задачах, стабильность в длинной сессии и итоговая цена одной полезной операции. Если речь о генерации медиа или голосе, дополнительно важны права использования, скорость, локальный запуск, качество русского языка и повторяемость результата.
Медиа из Telegram
Оригинальная публикация в Telegram
Дальше по теме
Еще несколько материалов из этого раздела.
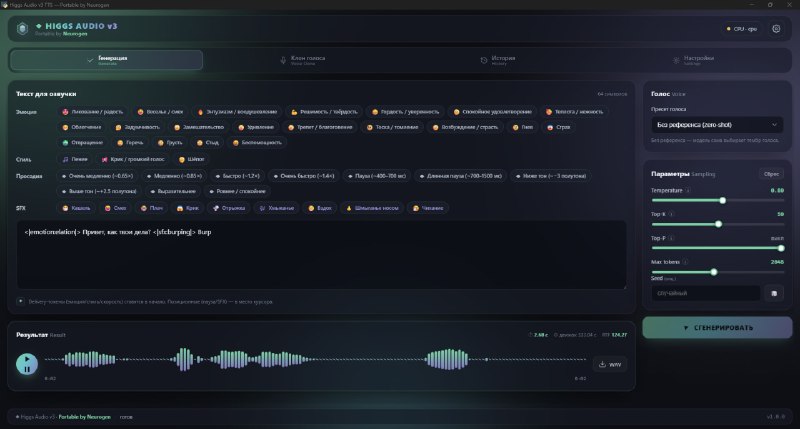 Higgs Audio v3 TTS [Portable by Neurogen]Портативка свежей модели синтеза речи от Boson AI — Higgs Audio v3 (4B) При первом запуске портативка сама определяет ваши комплектующие и подбирает нужную версию модели под ваше железо, если у вас совсем плохо по железу (4гб vram и меньше), то поративка направит всю нагрузку наHiggs Audio v3 TTS У нас очередная open-sourse TTS, но на этот раз все много интереснее, модель на 4B парамеHiggs Audio v3 TTS У нас очередная open-sourse TTS, но на этот раз все много интереснее, модель на 4B параметров, она также создана для живого общения, но умеет реагировать, делать паузы, расставлять акценты и держать диалог в риалтайме Есть русский В…
Higgs Audio v3 TTS [Portable by Neurogen]Портативка свежей модели синтеза речи от Boson AI — Higgs Audio v3 (4B) При первом запуске портативка сама определяет ваши комплектующие и подбирает нужную версию модели под ваше железо, если у вас совсем плохо по железу (4гб vram и меньше), то поративка направит всю нагрузку наHiggs Audio v3 TTS У нас очередная open-sourse TTS, но на этот раз все много интереснее, модель на 4B парамеHiggs Audio v3 TTS У нас очередная open-sourse TTS, но на этот раз все много интереснее, модель на 4B параметров, она также создана для живого общения, но умеет реагировать, делать паузы, расставлять акценты и держать диалог в риалтайме Есть русский В…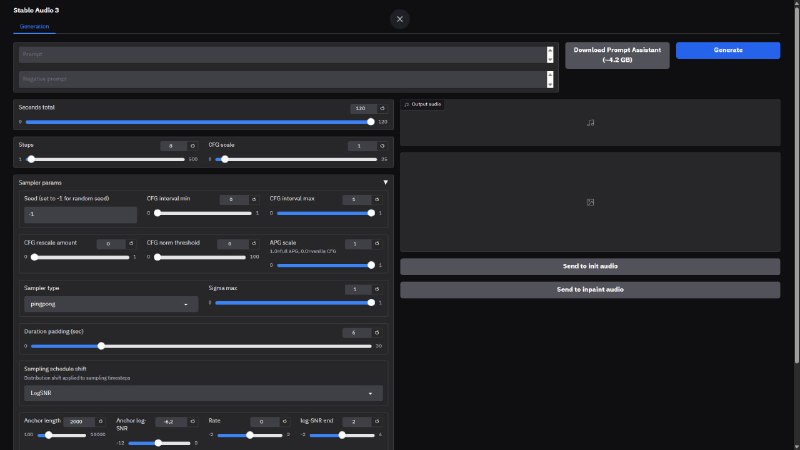 Stable Audio 3 Portable by NeurogenЛокальная генерация музыки и звуков из текста Stable Audio 3 - семейство открытых моделей для генерации аудио. Я собрал портативную сборку под Windows, чтобы запускать всё локально без танцев с pip, venv и CUDA 🔘Что внутри: - Stable Audio 3 Small-Music (433M) - музыка, до 120 сек
Stable Audio 3 Portable by NeurogenЛокальная генерация музыки и звуков из текста Stable Audio 3 - семейство открытых моделей для генерации аудио. Я собрал портативную сборку под Windows, чтобы запускать всё локально без танцев с pip, venv и CUDA 🔘Что внутри: - Stable Audio 3 Small-Music (433M) - музыка, до 120 сек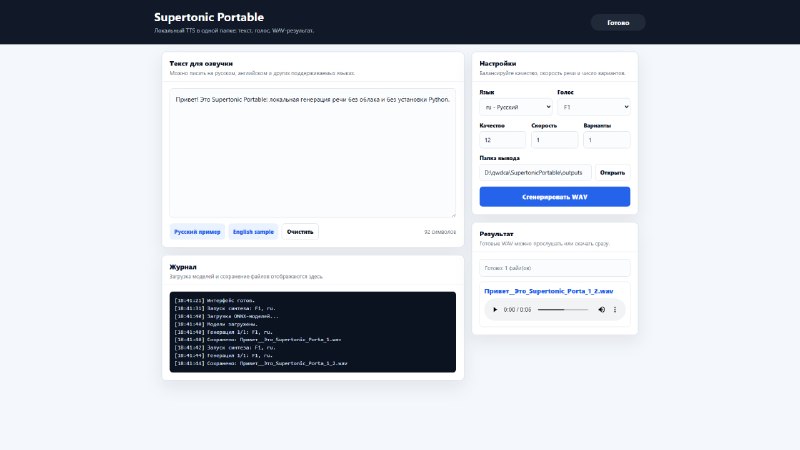 Supertonic Portable by NeurogenОчень быстрая TTS и давольно качественная. Все локально, запуск красивого и очень удобного интерфейса и всей портативки с одного батника Поддерживает 31 язык, качественный русский и английский На выбор 5 женских и 5 мужских голосов Скорость генерации несколько секунд, работает да
Supertonic Portable by NeurogenОчень быстрая TTS и давольно качественная. Все локально, запуск красивого и очень удобного интерфейса и всей портативки с одного батника Поддерживает 31 язык, качественный русский и английский На выбор 5 женских и 5 мужских голосов Скорость генерации несколько секунд, работает да
Обсуждение
Обсуждение начнется с первого вопроса или полезного дополнения.
Обсуждение еще не началось
После входа можно будет задать вопрос автору или ответить другим читателям.